LLMs, structured outputs and data generation
Augmenting, generating or retro-fitting data might be one of the coolest use cases for LLMs

LLMs are in the spotlight right now, from the largest companies to the lone hacker on Twitter, everyone’s talking about it.
While we are all still learning what these models can and can’t do effectively, it’s undeniable that they had, are, and will keep having a big impact on how people approach software development.
Recently, I’ve decided to take OpenAI’s ChatGPT 3.5 Turbo API for a spin, to tackle a problem that, I believe, is fairly common: ensuring that you can generate data on the fly based on already existing samples and perform what I just made up now to be “data retro-fitting”.
This experiment was all done in the context of a side project I have been working on for a little while, so, obviously, stakes are super low, mistakes are free to make, and data criticality is essentially non-existent. However, I feel like there are some really cool takeaways from this exercise, which is why I thought this would be worthy of a post.
Setting the stage
The context is a super simple app that shows recipes to a user, and offers possibilities to search for recipes by title (which will be unique, as we don’t want to have repeated recipes in the app).
Initially, this started very small, I simply used a SQLite DB which I seeded via a JSON file in memory:
def ingest_recipes_from_json(json_file, database):
conn = sqlite3.connect(database)
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS recipes (
id INTEGER PRIMARY KEY,
title TEXT UNIQUE,
ingredients TEXT,
preparation TEXT
)''')
with (open(json_file, 'r') as file):
recipes = json.load(file)
for recipe in recipes:
title = recipe.get('title', '')
ingredients = ', '.join(recipe.get('ingredients', []))
preparation = '\n'.join(recipe.get('preparation', []))
# Insert recipe into database, ignoring duplicates
cursor.execute('''INSERT OR IGNORE INTO recipes (title, ingredients, preparation)
VALUES (?, ?, ?)''', (title, ingredients, preparation))
conn.commit()
conn.close()This method sat in a file called `loader.py` which I can run myself, async, and decoupled from the application flow to seed my DB.
Obviously, the most important detail here is getting the JSON file in the first place, since it will be the data source for everything else I’ll have in the app.
Getting the data
So, now that I have a simple data model, a database to power my app, and an idea of what I want to do, all I needed was to get the actual data.
Getting the data in the old days before LLMs existed probably would involve a lot of manual work. Some glued-together Python scripts to maybe do some web crawling and massaging the data to fit exactly the format I was looking for to match my data model, clean the data and insert it into the DB.
However, with LLMs, this process is vastly simplified. My plan will be simple, I’ll ask ChatGPT 4o to generate me the JSON I’ll be using, and, in order to do that, a technique based on asking the LLM to generate structured output can be used.
The idea is that instead of simply saying:

we need to be much more detailed in our prompt, and guide the model to output the same information but in a JSON format exactly how we want it to be. So, let’s try again:
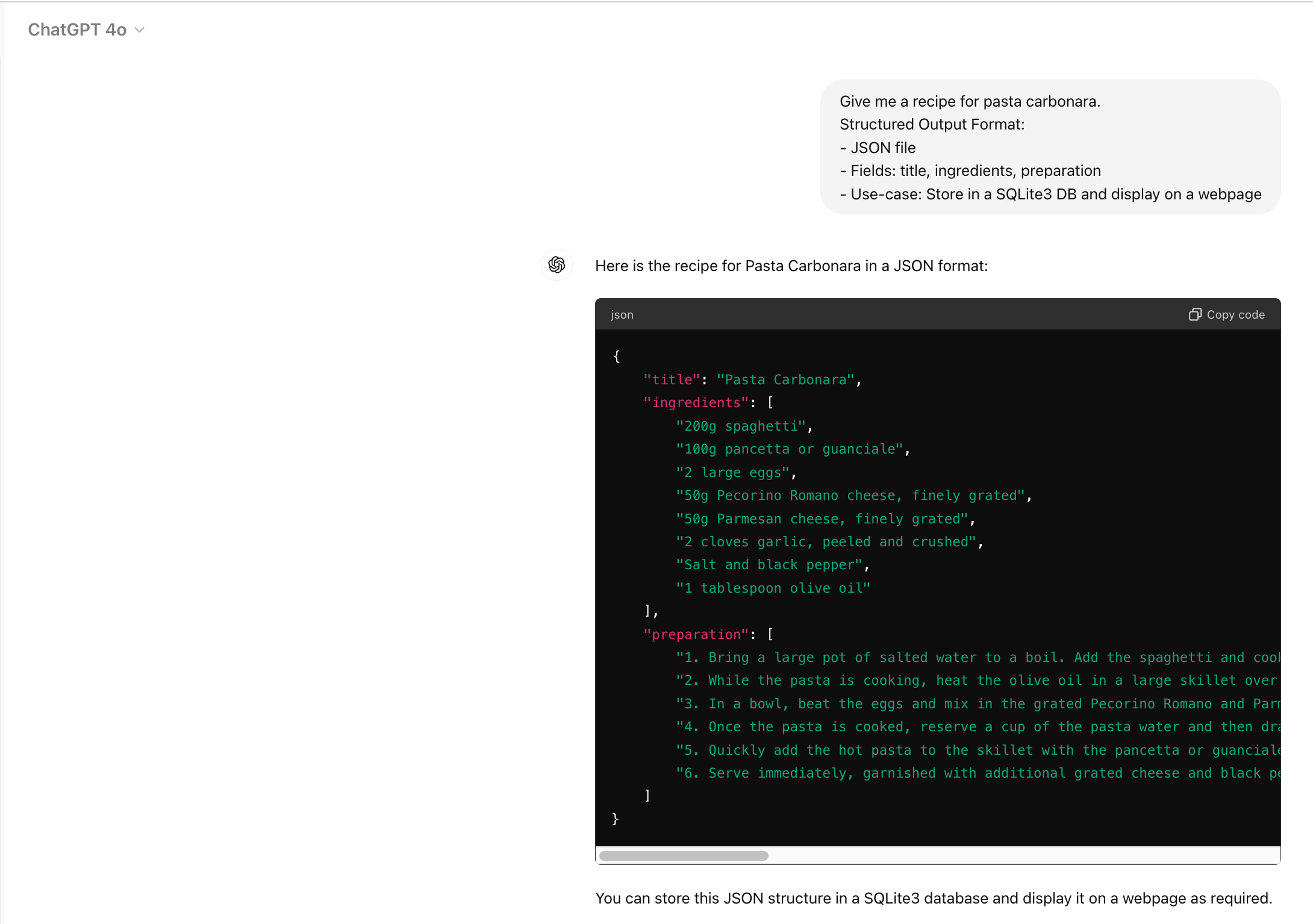
This is much, much better! With the above JSON being generated by the LLM, I can now just copy it and paste in my own JSON file, which I’ll use to seed my DB.
The best part is, these models are very good at learning from the current context, so, I can really do something that feels like magic:

Essentially, I didn’t need to do anything and I just got 5 very popular Portuguese recipes with the exact same format as before. I had no data, and, 2 minutes and a prompt later, I can now have endless recipes generated for me on-demand. I needed data, well, here I have it!
So, we can see just how efficient ChatGPT 4o is at generating data while following a structured output!
Extending the schema
This worked really well, my loader module was working well, I can load the data from a very large JSON file in-memory into my SQLite DB, and it all works!
Then, I had another idea to improve my app: what if we wanted to have two extra fields in my table, called `category` and `macros`.
The category would be if a given recipe is considered a weight loss recipe, a bulk recipe or one to maintain your current shape, and the `macros` field would have information on four classic metrics: protein, carbs, fat, and kcal per recipe.
Again, this data would be hard to get and ingest into my schema for all the recipes I already had, so, I took full advantage of my nimble setup. First, I simply introduced two new nullable fields in my DB table, got them from the JSON (remember, JSON generated earlier do NOT have these fields) and inserted them in the DB:
def ingest_recipes_from_json(json_file, database):
conn = sqlite3.connect(database)
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS recipes (
id INTEGER PRIMARY KEY,
title TEXT UNIQUE,
ingredients TEXT,
preparation TEXT,
macros TEXT NULLABLE,
category TEXT NULLABLE
)''')
with (open(json_file, 'r') as file):
recipes = json.load(file)
for recipe in recipes:
title = recipe.get('title', '')
ingredients = ', '.join(recipe.get('ingredients', []))
preparation = '\n'.join(recipe.get('preparation', []))
macros = None if recipe.get('macros') is None else recipe.get('macros')
category = None if recipe.get('category') is None else recipe.get('category')
# Insert recipe into database, ignoring duplicates
cursor.execute('''INSERT OR IGNORE INTO recipes (title, ingredients, preparation, macros, category)
VALUES (?, ?, ?, ?, ?)''', (title, ingredients, preparation, macros, category))
conn.commit()
conn.close()Super easy, right? SQLite3 and a side-project are such a great way of iterating on things FAST! :D
Then, the next step is to ask the LLM to start matching the new structure, by adding two fields to the JSON’s it outputs:
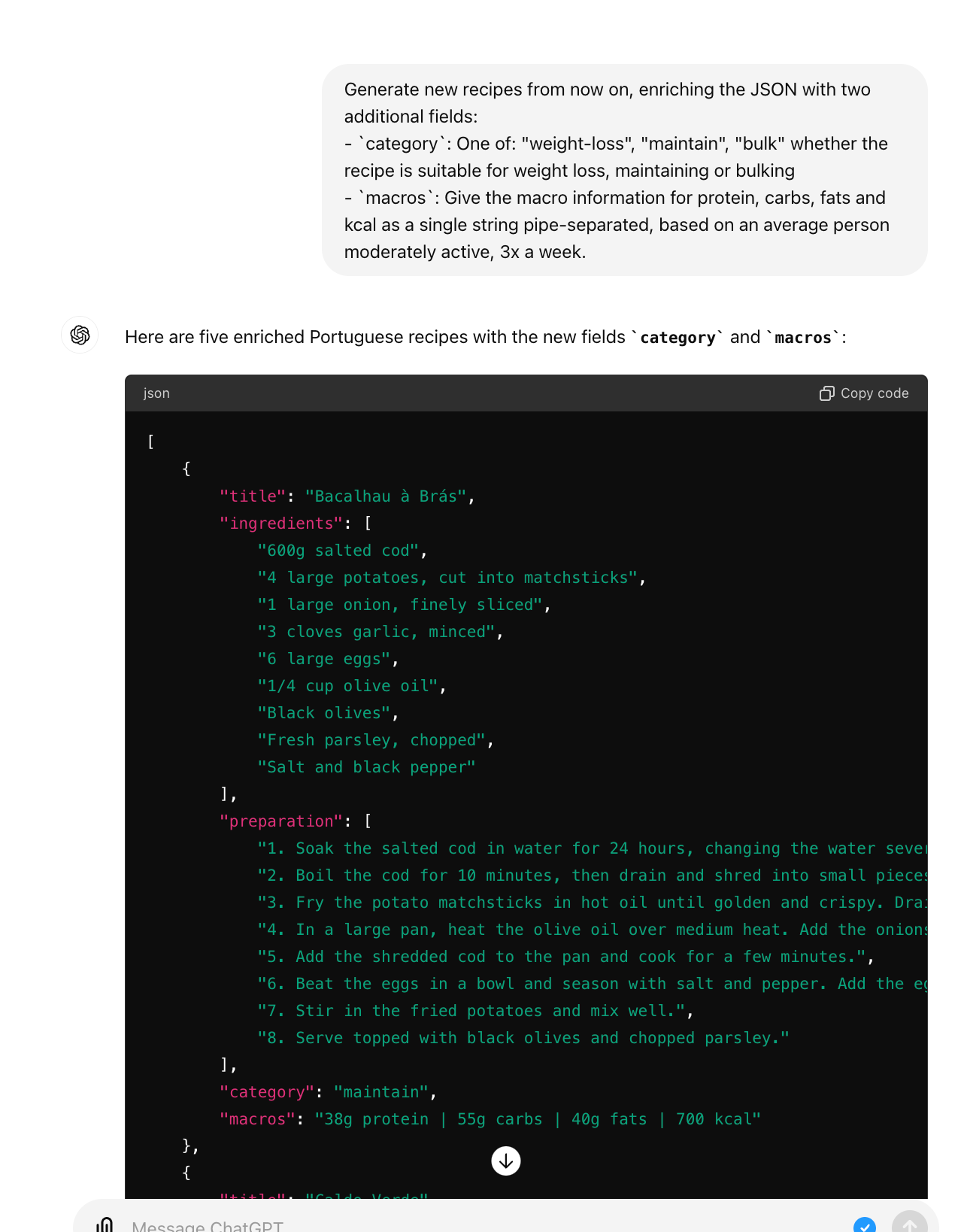
This is extremely powerful, as we can see: it managed to follow a complex formatting request to the letter while matching our new DB schema with basically no effort from our side. This is one of the areas where LLMs really shine through! If you give it good context and examples, prompt engineering alone can take you very far!
However, we have a new challenge now: I’ve already generated, stored and serve in production, in my app, over 400 recipes that do NOT have these extra fields, and it’s impractical, and very time-consuming to retro-fit all of these through the web UI of ChatGPT 4o, so, it looks like this is a job for the API.
We will follow a typical pattern that a lot of products and companies are adopting nowadays: we will add an “AI module” to our web app that interfaces with ChatGPT API to enrich our data “on-the-fly”.
Retro-fitting the data via the API
A nice pattern for designing software in general, either from scratch or extending existing one is to follow the simplest approach that works and adapt as your needs change.
With this principle in mind, our “AI module” (I should have called it LLM Module, but I digress) will be simply a top-level package that will have a dedicated file from where we can call the OpenAI API to perform our enrichment for us.
As always, we need to first see what exactly it is that we need to get out of it, what we have to offer it as input and how to steer the LLM towards giving us what we want.
In our case: we will call the API once, for every single JSON entry. We have ~400 entries, so we will make ~400 calls to the API, whose output will be exclusively the JSON containing the exact two fields we need: the `category` and `macros` one.
We could also optimize this and call it in bulk to generate a large JSON, and use the recipe titles to “match” the generated new fields per recipe, but, this way, at the expense of making much more calls to the API, we keep the logic really simple to follow. (This whole experiment costed a whooping 0.20 USD)
Additionally, and this is very important: our output size is both structured and small, so the chances of having hallucinations and/or wrong formats are much lower when focusing on one single JSON.
Here is our complete LLM module for this app, for now:
from openai import OpenAI
client = OpenAI(api_key='')
def enrich_existing_data(json):
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a technical assistant, skilled classification tasks and following "
"instructions."},
{"role": "user", "content": """
Input: The following JSON between %:
%"""+str(json)+
""""%.
Output a JSON with two fields:
- category: One of: maintain, bulk or weight-loss, as a string
- macros: A string, formatted as: Calories: XXX kcal |Protein: XX gr |Carbs: XX gr |Fat: XX gr
These will classify a meal into one of the categories and add the macronutrients information in the provided
format. Use as reference standard values for an average person, in their 30s, who is moderately active (3x a week).
Format: Output only the JSON with the two specified keys, but without the markdown formatter, start with
`{`. Do not use markdown formatters as I want to use the output directly.
"""}
]
)
content = completion.choices[0].message.content
print(content)
return contentThis is it!
Notice how, via the API, we can also give a system prompt to the model, to steer it even further and in a sense “prepare it” specifically for our enrichment task.
One caveat is that, since I used the ChatGPT 3.5 Turbo API, in some cases, the instruction-following isn’t perfect, so, to make this setup robust and efficient, I simply wrap up my “LLM call” in a try-catch and re-run any potential failures.
Re-running helps because the model starts with a completely fresh context on the entries it saw previously and, usually, re-running it is enough to fix any failures.
with (open(json_file, 'r') as file):
recipes = json.load(file)
for recipe in recipes:
title = recipe.get('title', '')
ingredients = ', '.join(recipe.get('ingredients', []))
preparation = '\n'.join(recipe.get('preparation', []))
category = recipe.get('category', None)
macros = None
if recipe.get('macros') is not None:
macros = "Calories: "+ str(recipe.get('macros')['calories'])+" kcal |"+"Protein: "+ str(recipe.get('macros')['protein'])+" gr |"+"Carbs: "+ str(recipe.get('macros')['carbs'])+" gr |"+"Fat: "+ str(recipe.get('macros')['fat'])+" gr"
else:
try:
macros_json = json.loads(enrich_existing_data(str(recipe)))
category = macros_json['category']
macros = macros_json['macros']
print(macros_json)
except:
print("Will be re-ran")
# Insert recipe into database, ignoring duplicates
cursor.execute('''INSERT OR IGNORE INTO recipes (title, ingredients, preparation, category, macros)
VALUES (?, ?, ?, ?, ?)''', (title, ingredients, preparation, category, macros))The really nice thing about this way of doing it is that the “LLM-flow” is truly hidden behind a very crude “interface” in our LLM module: from the perspective of the caller code, enriching the data with ChatGPT is just like calling any other function.
With some more work, if desired, this could be adapted in a number of ways to make it even more composable: you could let the caller code specify model versions, the system prompt and, with some extra runtime configuration, you could even call different LLMs other than ChatGPT.
Conclusion
LLMs are an amazing piece of technology, and, when we combine both good wrting and prompting skills together with what we already know about writing software for composable, modular, easy-to-read solutions, etc, we get a completely new framework for writing cool things that would be much harder before, but are now accessible to everyone!
Happy Prompting and Happy Coding!
PS: The app is live here! Drop a line in the comments if you cook something cool!